| e-gradiva | SERŠ Maribor | O projektu | Besednjak | ||||||
 |
|||||||||
| Osnove | Skladi | Topologije | Mediji | Pristopne | LAN | Omrežni | Transportni | Povezovanje | Varnost | Storitve | Varnost | Sistemi | Streniki | |||||||||
| e-gradiva | SERŠ Maribor | O projektu | Besednjak | ||||||
|
|||||||||
| Osnove | Skladi | Topologije | Mediji | Pristopne | LAN | Omrežni | Transportni | Povezovanje | Varnost | Storitve | Varnost | Sistemi | Streniki | |||||||||
V tej učni vsebini boste spoznali:
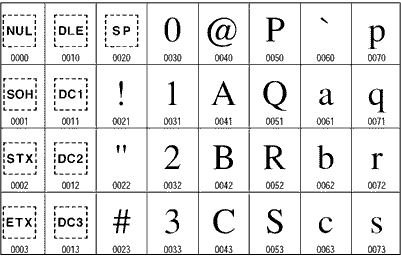
Del kodne tabele pisave ASCII (vir: Unicode)
![]()
Črke in drugi znaki so v računalniku predstavljeni tako, kot vsi drugi podatki, to je z dvojiškimi številkami. Znaki so urejeni s pomočjo tabel, imenovanih kodne tabele ali abecedni nabor znakov, ki povezuje grafično predstavitev nekega znaka z njegovim binarnim zapisom. Tako je za znak velike črke A v nekaterih kodnih tabelah ustrezno desetiško število 65 ali šestnajstiško število 41. V računalništvu se dvojiški številski sestav uporablja le na strojnem nivoju, na višjih nivojih se uporabljajo šestnajstiška števila, v uporabniškem vmesniku pa se število prikaže kot desetiško. Zaradi tega je potrebno biti previden in se prepričati, v katerem številskem sestavu je zapisano število.
Načini, kako slovenske znake predstaviti v računalniku, se precej razlikujejo, kar je pogosto tudi vzrok za mnoge težave s prenosljivostjo besedil. V uporabi je veliko število različnih kodnih tabel.
Dolžine zapisov kode znakov so enobajtne ali večbajtne. Dolžina je odvisna od tega, koliko različnih znakov želimo prikazati v kodni tabeli. Med enobajtnimi je zelo pogosta 7–bitna koda ASCII, ki uporablja dodaten bit za kontrolo podatkov. S sedmimi biti je mogoče opisati največ 128 različnih informacij (v našem primeru znakov). Z osembitno tabelo pa je mogoče prikazati 256 različnih znakov.
Sedembitno kodiranje je najstarejše in se še vedno uporablja tam, kjer v nobenem primeru ne sme biti težav pri prenosu dokumentov, na primer po elektronski pošti. Uporabno je tudi kot najmanjši skupni imenovalec, ki ga razume največja množica operacijskih sistemov in na njih vezane programske opreme. Žal pri tem v praksi šumnike pišemo kot sičnike in tako je besedilo zaradi tega včasih dvoumno. Precej znan je dvoumni primer: Problem je resen. Prednost sedembitne kode je malo število potrebnih bitov in zaradi tega so datoteke manjše. Zaradi omejitev, ki jih imajo sedembitna kodiranja, z napredkom izginjajo.
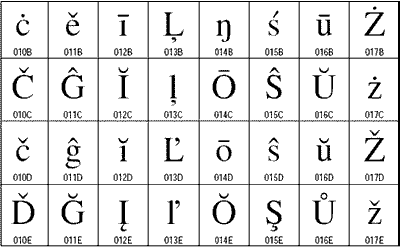
Del kodne tabele pisave Extended A (vir: Unicode)
Osemmbitno kodiranje je običajno razširitev sedembitnega. Spodnjih 128 znakov v osembitni je enakih ASCII, nadaljnjih 128 znakov pa je različnih glede na izbrano kodno tabelo. Od osembitnih kodiranj se pri nas največ uporablja kodiranje Latin2 (ISO-8859-2 ) na sistemih UNIX in CP852 ter CP1250 v Microsoftovih sistemih. Če se uporabi osembitno kodiranje slovenskih znakov, je kodiranje Latin2 prava rešitev, saj je kodiranje uvrščeno med mednarodne standarde, ki jih je potrdil ISO. Vsa druga osembitna kodiranja nimajo statusa mednarodnega standarda in so kvečjemu industrijski standardi, ki jih določajo nekatere programske hiše. Uporabljamo jih lahko le kot pomožno orodje, če smo kot osnovno izbiro ponudili katero izmed mednarodno standardiziranih možnosti.
Ljudje v različnih deželah zapisujejo svojo materinščino z različnimi črkopisi. Za prikaz svojega črkopisa (in še nekaterih drugih znakov) v večini jezikov zadostuje 8–bitna koda, v kateri lahko zapišemo 256 znakov. Težave pa se pojavijo:
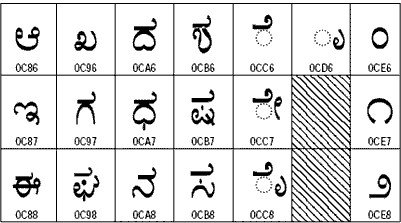
Del kodne tabele s pisavo Kannada (vir: Unicode)
Unicode lahko odpravi probleme različnih kodnih strani, prinese pa tehnično težavo: kako zapisati znake Unicode z 8–bitnimi zlogi? 8–bitni zlog je pri večini računalnikov najmanjša naslovljiva enota in tudi osnovna enota pri omrežnih povezavah s protokolnim skladom TCP/IP. Uporaba enega zloga za predstavitev enega znaka je zgodovinsko naključje, predvsem posledica dejstva, da se je razvoj računalništva pričel v Evropi in ZDA, kjer je 96 znakov zadostovalo za dolgo vrsto let.
Najbolj uporabljana standarda Unicode sta:
Več o standardu lahko poiščete na spletipču Unicode.

Del kode XHTML
Znakovna referenca so številke ali simbolična imena za znake, ki se vključujejo v dokumente XHTML. Uporabljajo se za redko uporabljene znake, ki bi jih avtor strani težko vnesel. Znakovna entiteta se prične z znakom &, oznako in se zaključi s podpičjem ;. Vmes pa se napiše desetiško število kode Unicode, črko x in šestnajstiško vrednost kode Unicode ali pa ime znaka. V XHTML je potrebno kodirati tudi nekatere znake iz tabele ASCII, ki so del jezika XHTML, na primer < za znak <. V besedilu, ki je na sliki, so z modro barvo označeni elementi jezika XHTML, z vijolično pa znakovne reference.
Nekaj primerov:
< predstavlja znak <,> predstavlja znak >," predstavlja znak ",Č (decimalno) predstavlja veliko črko C s kljukico nad njo: Č.И (decimalno) predstavlja veliko črko I v cirilici: И.水 (šestnajstiško) predstavlja kitajski znak za vodo.
![]()
![]()
![]()
Za kodne tabele je v ISO/OSI zadolžena predstavitveni sloj. Večina protokolnih skladov pa teh storitev ne zagotavlja na tem sloju. Za kodne tabele so zato zadolžene aplikacije. V preteklosti je bilo pomembno, da so bile kode znakov zapisane čim krajše in so posledično imele manj znakov. Danes je mogoče s tabelami Unicode zapisati znake skoraj vseh jezikov.

Izvedbo projekta je omogočilo sofinanciranje Evropskega socialnega sklada Evropske unije in Ministrstva za šolstvo in šport.